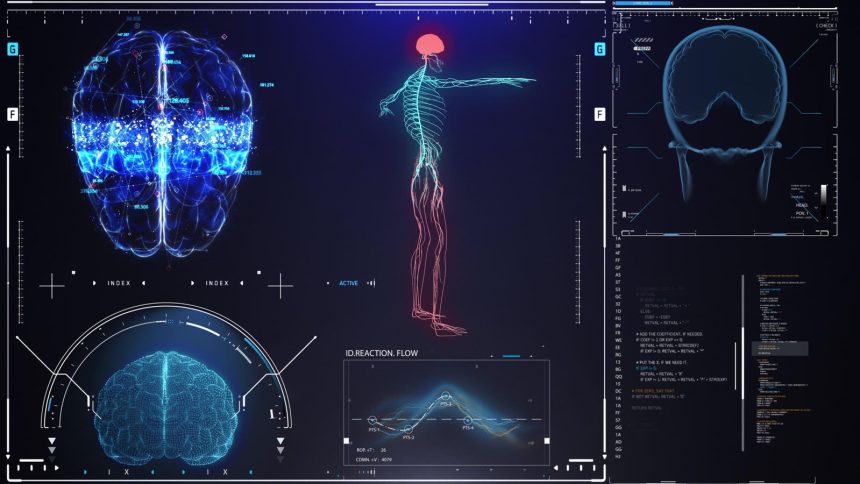
A joint venture between Aidoc and AWS to revolutionize clinical AI solutions
Over the past year, AIDOC, a leader in clinical AI solutions, and NOVA菌, a global leader in cloud computing, have collaborated on a significant investment aimed at shaping the future of medical AI. The partnership is crucial as it seeks to address critical gaps in the field, such as the need for faster and more accurate solutions for precision medicine.
The公司的 Clore, a "glassdoor" term for the AI foundation model, holds a foundation built on multimodal data and advanced algorithms. This foundation is designed to empower clinical teams with crucial tools: speed and accuracy. AWS, renowned for its expertise in cloud computing, is committing a multi-year investment to strengthen AIDOC’s research and development efforts. This move is expected to double AWS’ share of AIDOC’s net income, a signal of significant growth and ambition.
AIDOC’s Rib Fractures system is a prime example of this collaboration’s success. The system, developed using AWS’ proprietary AI platform aiOS, has achieved FDA clearance, marking a milestone in the company’s efforts to supply precision medicine solutions. The system leverages advanced algorithms and multimodal data to provide immediate, evidence-based diagnostic tools, enhancing the accuracy of radiation assessments in the clinical setting.
ELAD WALACH, CEO of AIDOC, highlighted the profound impact of their partnership. “Clinical AI is creating a massive field and is poised for monumental progress,” he noted. “Yet, we are just beginning to move forward. Our partnership with AWS is not just funding our R&D but is a step toward realizing significant patient outcomes.” This partnership represents a profound shift for the company, embodying the potential of advanced AI in healthcare.
The collaboration with NOVA菌 is not just about technical innovation but about redefining the role of AI in medicine. By collaborating closely with stakeholders such as antiquated standards and patient care, aidoc aims to make AI a tool that aids, rather than hinders, the precision and outcomes of medical treatment. This perspective underscores the necessity of tailoring AI technologies to the specific needs and constraints of clinical practice.
The evolution of AI in healthcare is unequivocal: now, while most companies still focus on pilot programs and preliminary applications, it is crucial for enterprises to consider the real-world applications of their technologies. This shift begins with医疗机构 who are emotionally attuned to the challenges they face. Such a move byYOxnaan, advancing rapidly, aims to bridge gaps in healthcare accessibility and access to modern diagnostic tools.
As the AI ecosystem continues to evolve, the next phase is focused on integrating clinical-specific applications and ensuring that these technologies meet the needs of飾ists. The growth of AI in fields like dermatology and pathology highlights the growing potential of this technology, but as with any innovation, it requires time to fully realize its impact. With increased investment, advancements, and patient satisfaction, further opportunities for impactful AI solutions in healthcare promise to transform the future of precision medicine.

